
英语原文共 11 页,剩余内容已隐藏,支付完成后下载完整资料
毕业论文(设计)
英文翻译
原文标题 Quantized Convolutional Neural Networks for Mobile Devices
译文标题 面向移动设备的量化神经网络
面向移动设备的量化卷积神经网络
Jiaxiang Wu1, Cong Leng, Yuhang Wang, Qinghao Hu, Jian Cheng
1 中科院自动化所模式识别国家重点实验室,中国,北京
摘要:最近卷积神经网络在众多计算机视觉任务上有着优秀的表现。然而,卷积神经网络的应用由于高计算复杂度的限制使得高性能的硬件成为必备条件。在这篇论文中,我们提出了一个名叫量化卷积神经网络来同时加速计算并减少网络的存储容量。卷积层和全联接层中权重矩阵的滤波核被量化用于最小化每层响应的预测误差。在ILSRC-12数据平台上的拓展实验显示Q-CNN在仅有1%分类准确性的损失下可以达到4到6倍的加速和15到20倍的压缩效率。通过我们的量化卷积神经网络,即使移动设备也可以准确地在1秒内对图像进行分类。
关键词:卷积神经网络,量化,
介绍
最近几年,我们已经见证了卷积神经网络在一系列视觉应用上的巨大成功,包括图像分类、目标检测、年龄预测等等。这些成就主要来自更深层次的网络结构和海量的训练的数据。然而,随着网络变得更深,模型的复杂度在训练和测试阶段也会成指数级增长,从而导致对计算能力有很高的要求。比如,8层的Alexnet包含60M的参数和需要超过729M的浮点型运算来分类一张简单的图像。虽然训练阶段可以通过GPU离线加速来获得高质量的分类表现,但测试的计算代价对于个人电脑和移动设备是无法承受的,由于计算能力和存储空间的限制,移动设备几乎不能去运行卷积神经网络,因此,对于卷积神经网络而言加速计算和压缩存储空间是非常有必要的。
对于大多数的CNN,卷积层消耗绝大多数的时间而全联接层则包含大量的网络参数。因为它们的内部差异,已有的网络通常着重于提高卷积层和全联接层的效率。在[7,13,32,31,18,17]中,低秩近似和张量分解被用于加速卷积层。另一方面,全联接层的参数压缩则涉及于[3,7,11,30,2,12,28]。总体上,上述涉及的算法能够获得更快的速度和更少的存储空间。然而,它们对于整个网络很少能同时取得有效的加速和空间的压缩。
本文基于CNN提出统一的框架Q-CNN,能在极少的表现损失下来同时加速和压缩CNN模型。通过量化网络参数,卷积层和全联接层的响应可以通过内积计算来有效的预测。在参数量化中,我们最小化每层的预测误差来更好的保持模型的原有的表现。通过采取一种考虑先前预测误差的训练策略来压缩量化多层产生的累积误差,我们的Q-CNN能够在测试阶段加速计算并有效的减少存储空间。
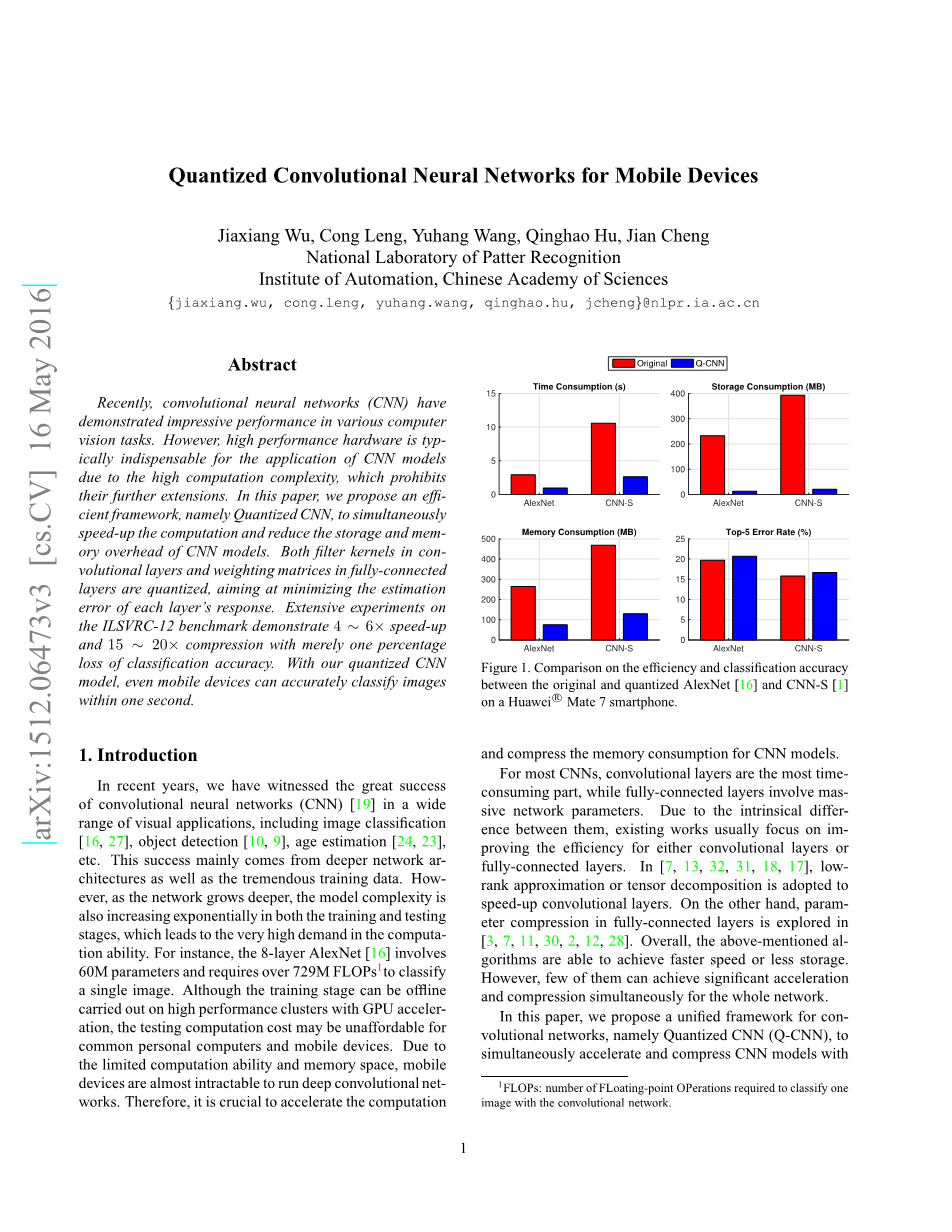
我们在MNIST和ILSVRC-12两个数据平台上来评估Q-CNN在图像分类的表现。在MNIST上对两个无卷积的神经网络运用Q-CNN方法取得了12倍的压缩,对比其它几个方法仅有极少的准确性损失。在ILSVRC-12上我们尝试对四个CNN:Alexnet,Caffenet,CNN-S和VGG-16提高测试阶段的效率。Q-CNN在每个网络上大体上取得了4倍的加速和15倍甚至更高的压缩效率,在top-5分类准确性上有1%的损失。另外,我们将Q-CNN运用在移动设备上极大地提高了测试阶段的效率如图一所示。本文的主要工作总结如下:
我们提出了一个统一的Q-CNN框架来加速和压缩卷积网络。我们提出通过最小化每层响应的预测误差可以很好得进行量化。
在量化整个卷积神经网络中,我们提出了一个有效的训练策略来压缩累积误差。
我们的Q-CNN在损失1%的准确性下取得了4到6倍的加速和15到20倍的压缩。另外量化的CNN模型可以应用在移动设备上在一秒内完成图像分类。
预备知识
在卷积神经网络的测试阶段,卷积层占用了大多数的计算时间。同时,全联接层储存了网络中的大多数参数。因此,为了获得更好的测试效率,加速卷积层和压缩全联接层的参数极为重要。
我们观察到在卷积层和全联接层的前向处理过程中,内积占据了绝大数的计算。一般地,我们考虑一个卷积层的输入特征映射和响应特征映射,其中,是空间大小,是特征映射通道数。在第层特征映射的2维空间位置处的响应为:。其中,是 第个卷积核,为核的大小。我们用和来定义位于输入特征映射和卷积核的2维空间位置,和是维向量。层响应为的感受野对输入特征映射的所有位置进行内积的和。
类似的,对于一个全联接层,我们有,其中S,为层输入和层响应。分别地,为该层第 个神经元的权重向量。
乘积量化被广泛应用于最近邻搜索,比哈希方法表现得更好。它是将特征空间分解成多个子空间的笛卡尔积并对每个子空间学习它的字典。用向量表示的子字典的级联可以有效得计算距离和存储。
本文运用乘积量化来有效得实现内积运算。考虑之间的内积运算,首先,将x和y分成M个子向量,定义为和,每一个由第m个子字典中的一个子码字量化。则有,如果第m个子字典中的所有子码字和每个子向量之间的内积都提前计算得到,那么D维的向量内积运算就可以转化为M个和运算。
基于量化的方法在许多工作[11,2,12]中都有研究过。这些方法主要着重于对全联接层参数的压缩,但并不能对测试阶段提供加速计算。另外,[11,12]中需要网络参数在测试阶段被重构从而限制了硬盘压缩并增加了内存消耗。相反的,我们的方法对卷积和全联接层同时提供了加速和压缩,并且能极大的减少了运行时的内存空间。
3.Q-CNN
我们在这部分提出加速和压缩卷积神经网络的方法。首先,我们介绍一种通过量化网络参数来有效地进行测试阶段的计算过程。其次,我们发现直接通过最小化每层响应的预测误差可以更好地进行量化。最后,我们分析了我们量化CNN模型的计算复杂度。
3.1量化全联接层
对于一个全联接层,我们定义它的权重矩阵,和分别为该层的输入和响应。权重向量为W中第列。
我们将维的空间平均分成M个子空间,每个子空间为维。那么每个就被分解成M个子向量。定义为.将此子空间的所有子向量聚合可以学得该子空间的子字典。通常的,对第m个子空间,我们最优化:
s.t. , (1)
为权重向量矩阵的第m个子向量集(矩阵)。字典由K个原子组成,中的每一列是一个指引向量来阐明哪一个原子被用来量化相应的子向量。最优解可以通过K-means聚类解决。
层响应被近似计算成:
. (2)
其中,是中的第个列向量。是该层输入的第m个子向量。是用来量化子向量的原子索引。
通过将权重矩阵分解成M个子矩阵,学得每一个子空间的字典。在测试期间,层输入被分成M个子向量集定义为.对于每一个子空间,我们计算和中的每个原子的内积,并将该结果储存。这样可以通过M个和运算得到每层的响应。因此,总体上的运行时间复杂度将从减少到。另一方面,只需保存子字典和量化索引来极大的减少储存消耗。
3.2量化卷积层
不同于全联接层的1维权重向量,每个卷积核是一个三维的张量:。在量化之前,我们需要决定如何将它分解为子向量,子空间分为几维等。在测试期,输入特征映射通过具有固定空间区域的卷积核进行滑动。由于这些滑动窗口部分重叠,我们根据特征映射通道的维数来分解每个卷积核,所以在多个空间位置的计算
s.t. , (3)
能再利用之前预计算的内积结果 。特别地,我们量化每个子空间得到:
包含了在位置处所有卷积核的第m个子向量。对每个子空间,最优解同样可以通过k聚类得出。
量化卷积核后,我们近似计算特征映射的响应:
(4)
为输入特征映射中位于处的第m个子向量。用于量化位于第个卷积核中位置的原子索引。
和全联接层类似,我们预计算输入特征映射的内积表。然后,特征映射的响应用公式7近似计算,可以极大的减少运行时间和储存空间。
3.3误差校正量化
到目前为止,我们已经提出了一种直观的方法来量化卷积网络的参数和提高测试阶段的效率。但是,还有两个主要缺点。 首先,最小化量化误差的模型参数不一定给出最优量化网络的分类准确性。 相反,最小化每层响应的估计误差与网络的分类性能密切相关。 其次,每一层的量化是独立于其它层,这可能会导致量化多层时误差的累积。由于之前量化层引入的误差会影响下层,所以网络最终响应的预测误差很可能迅速积累。
为了克服这两个局限性,我们对网络参数量化引入误差校正。这种改进的量化方法直接最小化每层反应的估计误差,并可以补偿之前层引入的误差。通过纠错方案,我们的量化网络比原始量化方法仅有少量的性能损失。
3.3.1全连接层的误差校正
假设我们有N个图像来学习一个完全连接层,以及层的输入和响应图像In表示为Sn和Tn。为了最小化层响应的估计误差,我们优化:
(5)
其中在F范中的第一项是层响应的期望值,第二项是通过量化参数计算的近似层响应。可以应用块坐标下降法最小化这个目标函数。 对于第m个子空间,它的残差定义为:
(6)
然后,我们尝试最小化该子空间的残差:
(7)
并且可以通过交替更新子码本和子码字分配来解决上述的优化。
更新。我们固定子码字分配,并定义.(10)中的优化可以重新写为:
(8)
这意味着优化一个子码字并不影响其他子码字。 因此,对于每个子码字,我们从(11)中构造一个最小二乘问题来更新它。
更新。固定子码本很容易发现对中每列的优化是相互独立的。 对第t列,它的最优子码字分配由下式给出:
(9)
3.3.2卷积层的误差校正
我们采用相似的想法来最小化的卷积层特征响应的估计误差,即:
(10)
优化也可以通过块坐标求解.解决这个优化问题的更多细节可以在补充材料中找到。
3.3.3多层误差校正
上述量化方法可以顺序地应用到CNN模型中的每个层。忧虑是上一层引起的层响应估计误差将积累并影响量化下一层。这里,我们提出有效的训练方案来解决这个问题。
我们考虑特定层的量化,并且假设其以前的层已经被量化。参数量化的优化是基于该层的输入和一组训练图像的响应。来量化这个层,我们将量化网络中的层输入设为{},以及原始网络中的层响应(未量化)设为方程式中的{}。通过这种方式,优化过程由量化网络中实际输入和原始网络的期望响应引导。被前层引入的累积误差考虑进优化中。因此,这种训练策略可以有效地压缩多层量化中的累积误差。
另一种可能的解决方案是在所有量化层中采用反向传播来共同更新子码本和子码字分配。 但是,由于子码本分配是离散的,基于梯度的优化相当困难。因此,这里不采用反向传播,但将来可以进行扩展。
3.3.4计算复杂度
现在我们分析测试阶段量化和无量化的卷积层和完全连接层的计算复杂度。对于我们提出的Q-CNN模型,每层前向过程主要包括两个步骤:内积的预计算,以及层响应的近似计算。 两个子代码本和子码字存储用来测试阶段的计算。 我们在表1中详细得比较计算和存储开销。
表1. 卷积和完全连接层计算和存储开销的比
从表1可以看出,计算的减少和存储开销主要取决于两个超参数,M(子空间数)和K(每个子空间中的子码字)。 大数值的M 和K会导致更细粒度的量化,但在计算和存储消耗方面效率较低。 实际上,我们可以改变这两个参数来平衡在测试阶段的效率和量化CNN模型精度损失。
4最近的工作
对试验阶段卷积网络计算的加速已经有许多的尝试,许多受到低秩分解的启发。 Denton等[7]提出了一系列对卷积内核低秩分解的设计。类似的,CP分解用来将卷积层转换为具有更小的复杂度的多层。张等人在[32,31]在学低秩分解时考虑了非线性单元。 [18] 采用群微调来将卷积张量分解成稀疏密集矩阵的乘法。最近,在[5,25]探讨了基于固定点的方法。 通过将连接权重替换成固定点的数量,计算可以很大程度上受益于硬件的加速。
<p
剩余内容已隐藏,支付完成后下载完整资料</p
资料编号:[26518],资料为PDF文档或Word文档,PDF文档可免费转换为Word
课题毕业论文、开题报告、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。
您可能感兴趣的文章
- 饮用水微生物群:一个全面的时空研究,以监测巴黎供水系统的水质外文翻译资料
- 步进电机控制和摩擦模型对复杂机械系统精确定位的影响外文翻译资料
- 具有温湿度控制的开式阴极PEM燃料电池性能的提升外文翻译资料
- 警报定时系统对驾驶员行为的影响:调查驾驶员信任的差异以及根据警报定时对警报的响应外文翻译资料
- 门禁系统的零知识认证解决方案外文翻译资料
- 车辆废气及室外环境中悬浮微粒中有机磷的含量—-个案研究外文翻译资料
- ZigBee协议对城市风力涡轮机的无线监控: 支持应用软件和传感器模块外文翻译资料
- ZigBee系统在医疗保健中提供位置信息和传感器数据传输的方案外文翻译资料
- 基于PLC的模糊控制器在污水处理系统中的应用外文翻译资料
- 光伏并联最大功率点跟踪系统独立应用程序外文翻译资料


